Measuring Context Pollution in Agentic Systems
Leaky prompts create context pollution that degrades agent performance over time. As agents take on longer, more complex workflows, maintaining alignment with the user’s intent becomes a system problem. A conversation can accumulate revisions, side paths, clarifications, and stale context until the agent is no longer planning from the right informational environment.
Context pollution measures that degradation. It captures the semantic distance between the user’s original intent and the agent’s current working context, giving the system a concrete signal for when re-anchoring or correction is required.
Defining Context Pollution
Context pollution is the measurable distance between original intent and current direction, created by the natural entropy of complex interactions.
Formula
Definition
- CP = Context Pollution (range: 0 to 1, higher is worse)
- S(anchor, current) = Cosine similarity between the embedding of the user’s original intent and the current working context embedding
A similarity score of 1.0 means perfect alignment with the user’s original intent. As that score drops, the context pollution grows, signaling increasing semantic divergence.
Risk Interpretation
Context pollution becomes actionable at defined thresholds.
| Context Pollution | Risk Level | Interpretation |
|---|---|---|
| < 0.10 | Aligned | User intent and active context are strongly aligned. No corrective action needed. |
| 0.10–0.25 | Mild Drift | Minor drift detected. Performance quality may begin to degrade. Review for subtle misalignment. |
| 0.25–0.45 | Noticeable | Significant drift from the user’s original intent. Agent responses may be off-topic or underperforming. |
| > 0.45 | High Risk | Severe misalignment. System is likely optimizing against outdated or polluted context. Re-anchoring required. |
These thresholds turn drift into a decision point—the system either stays within bounds or triggers intervention.
Deep Research Workflow Example
Drift detection becomes concrete when built into the workflow itself. Consider an agentic research assistant helping with a complex analysis project:
- Initial context gathering: Agent gathers background on the research topic, identifies key search parameters, and proposes a research plan
- Anchor creation: Once the user agrees the agent has the correct plan, the user’s intent and agreed context are stored as the anchor embedding
- Research execution: Agent performs searches and begins building a comprehensive report
- Extended interaction: User digs into specific sources, asks follow-up questions, and requests clarifications over multiple turns T(x)
- Drift detection: Agent periodically compares current context against the anchor embedding to check for semantic drift
- Threshold decision:
- If drift < acceptable threshold (e.g., 0.25): Agent continues with current trajectory
- If drift > acceptable threshold: Agent initiates clarification sub-loop to realign intent and context
- Re-anchoring: On user acceptance of clarifications, agent creates a new anchor embedding
- Workflow continuation: Research continues with updated alignment reference
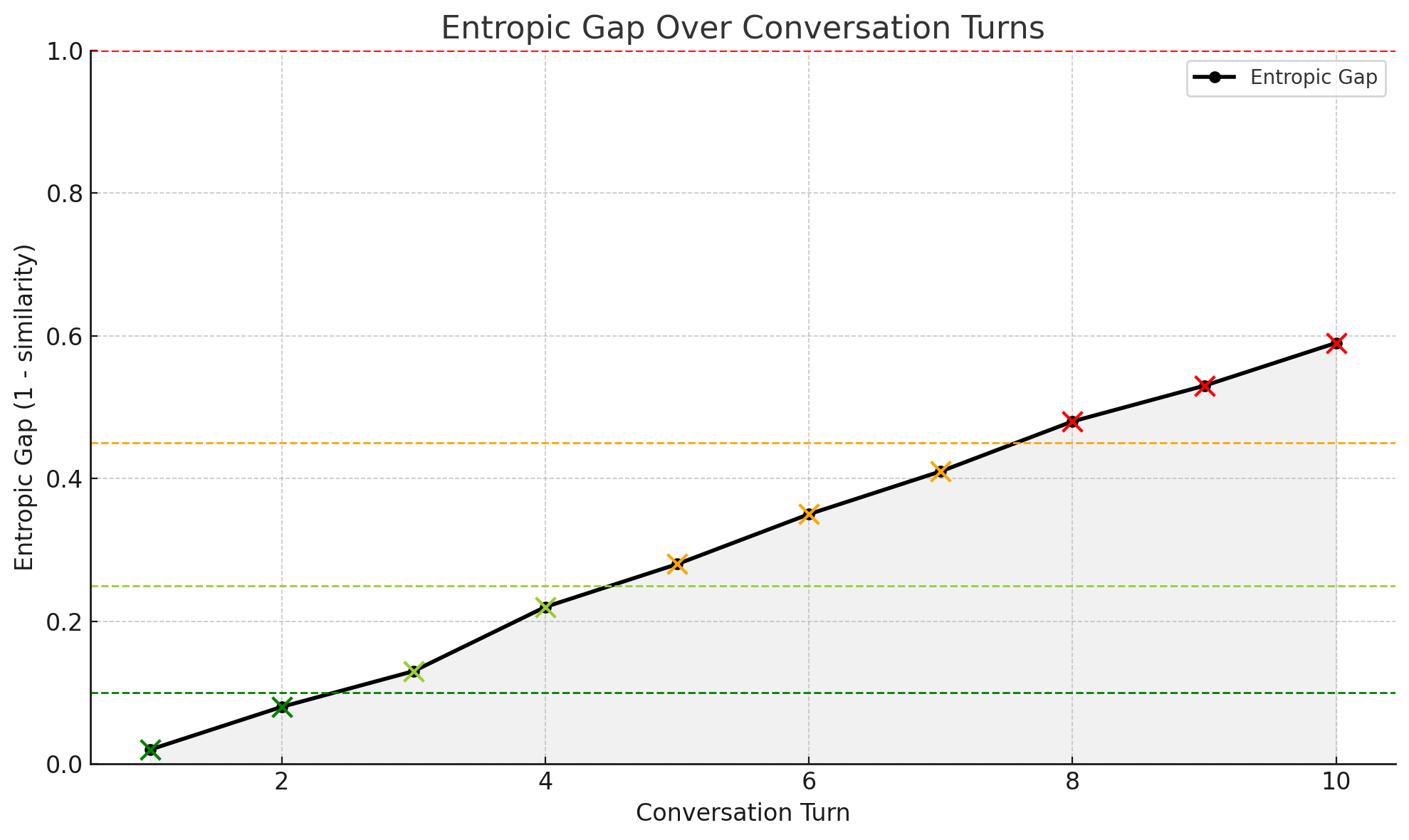
The visualization shows semantic drift increasing over successive interactions—the pattern context pollution measurement is designed to detect.
Re-anchoring does double duty. It realigns the agent with the user’s original intent and the authority boundaries attached to that work, and it manages context window limits by pruning outdated conversation history. The agent stays within bounds semantically and technically. Sessions continue indefinitely without degrading from drift or truncation.
Causes of Drift and Decay
Leaky prompts are predictable outputs of unstructured conversations. The gap emerges from two core dynamics:
- Intent drift: The user’s original intent loses clarity as instructions evolve without reaffirmation.
- Contextual noise: Corrections, side discussions, and metadata accumulate and distort the working memory.
Unlike humans, who can filter and prioritize context, LLMs treat all context as equally relevant unless instructed otherwise. As a result, they often overfit to noise, optimize away from the user’s intent, or respond to outdated goals.
Leaky Prompts explores why these failure modes emerge. This post provides the measurement layer.
Connecting Drift to System Failures
Context pollution provides a quantitative signal. Pairing it with qualitative evaluations—test failures, unexpected outputs, annotated breakdowns—maps how drift contributes to downstream failure.
Connecting Measurement to Failure
Drift detection requires more than similarity scores. Connecting measurement to operational outcomes creates a diagnostic chain with three components:
- Drift curve: how far the system has moved from original intent
- Eval outcome: whether the intended work succeeded, failed, or degraded
- Interaction pattern: where and when breakdown occurred in the session
When these three signals align, failures trace back to specific moments of semantic divergence.
Common Failure Patterns
Different types of drift produce distinct failure signatures:
- Sharp drift early in a session often results in intent confusion or tool misfire
- Gradual drift over time may lead to vague, repetitive, or hallucinated responses
- Low drift but high failure indicates a different cause—likely memory constraints, tool errors, or retrieval failures
From Measurement to Action
Connecting context pollution data to known failure points classifies failure modes by shape and trajectory:
- Drift signature mapping: clustering different types of decay into recognizable patterns
- Root cause visibility: identifying which type of drift leads to which kind of breakdown
- Early intervention design: triggering recovery mechanisms before user-visible errors occur
Drift treated as a system-wide variable—not just a user experience detail—creates an alignment layer across the entire agent. The question shifts from “what went wrong” to “when did it start, how far did it go, and what did the system try to do before it broke.”
Strategies to Track and Control the Gap
Drift prevention is an architectural principle, not a debugging tool.
- Anchor reference embeddings: Save a vector representation of the user’s original intent to continuously compare against the evolving context.
- Drift visualizations: Plot the Context Pollution over time to reveal when and how semantic misalignment occurs.
- Context pruning: Remove irrelevant, outdated, or conflicting turns from the prompt history.
- Intent reinforcement: Reiterate the user’s intent every few turns or whenever drift exceeds a certain threshold.
- Reset triggers: If CP exceeds 0.45, initiate re-anchoring prompts or system-initiated clarifications.
These architectural decisions create self-correcting workflows—the same generate-validate-correct pattern described in Agentic Self-Correction, applied to context alignment rather than output structure.
How Agents Can Help Close the Gap
As models improve, agents will not just suffer from drift—they will help detect it. An agent that can compute its own context pollution can detect when a user has unintentionally changed direction, suggest re-anchoring, and signal drift before it becomes a failure.
This is the responsibility model in action. The agent operates within its responsibility—planning and outcomes—by monitoring its own alignment. The human retains judgment. The agent surfaces the signal that makes judgment possible. Drift detection does not give the agent more authority. It gives the human better visibility into whether the agent is still operating within the authority it was given.
Why It Matters Now
As agents become embedded in multi-step workflows and long conversations, maintaining alignment with the user’s intent becomes critical. A 2% misalignment early in the chain can create a 40% failure rate by the end.
Context pollution makes that misalignment visible before it reaches the user. It is to agent coherence what latency monitoring is to system performance—not optional once the system is in production.
Conclusion
Leaky Prompts describes the failure mode. Context pollution describes the technical cause. Context pollution measurement provides the signal that makes intervention possible.
Measurement without action is monitoring. Measurement with action—re-anchoring, context pruning, threshold-triggered intervention—is the beginning of self-correction. The agent detects its own drift, surfaces the signal, and either realigns or escalates. Context management defines the environment. The measurement layer tells you when that environment is degrading. The correction loop brings it back.
The best agent systems will not be those that start strong. They will be the ones that stay aligned.